Have you ever heard a familiar voice on the radio or TV but couldn\’t remember whose it was? Similar information recalling to those happening in your brain during these activities can now be performed by artificial intelligence (AI). By combining natural language processing (NLP) and machine learning (ML), it can evaluate whether the system has encountered a voice before and how confidently it can pinpoint it, saving you the brain effort.
Speaker recognition, identification and verification is not an entirely new research topic. Since the 1990s, researchers have been publishing studies on new techniques to identify a specific person by their voice alone, independent of the spoken text. Our SpeakerID system is based on convolutional neural networks (CNNs) that can isolate relevant acoustic data from a very short voice recording to create a specific speaker sample (voice print).
A new audio recording is then compared with the database thus created – for example, from publicly available media data from television and radio broadcasting. The samples are triple-checked for similarity to confirm the positive identification of the voice. The name of the correct speaker is automatically inserted into the transcript, including a pre-stored role (e. g. TV host, minister, reporter, etc.). If the identification confidence of an analyzed voice is insufficient or the sample is very similar to more than one voice print in the database, the system prefers to leave the speaker unrecognized to avoid misidentification.

The database of voice prints is tailor-made for each customer; we do not share information about the speakers with anyone, nor do we publish information about any voice samples. However, we do keep the database up to date, since voices may change slightly over the course of a lifetime, as does the recording technology. Therefore, adding new samples to already stored speakers helps with the probability of future positive identification.
What can SpeakerID do for you?
The automatic addition of the speaker\’s name in the recording and its functionality has many benefits, such as improved accuracy. In most cases, manual identification involves lengthy research, unless it is a highly specific voice. Oftentimes this is complicated further by the written form of a given name – with SpeakerID you are not at risk of typos or mix ups of similar names, as the saved speaker\’s name is always checked, and their role or function updated. So, for example, if you were transcribing an interview with a politician who has changed their position within the party several times, you would see their most recent role.
Furthermore, SpeakerID can help when transcribing only a part of a program or interview and you cannot find the name of the presenter or a well-known guest who appeared in that passage. It also speeds up the editor\’s work by assigning the speaker to each occurrence, not just their first.
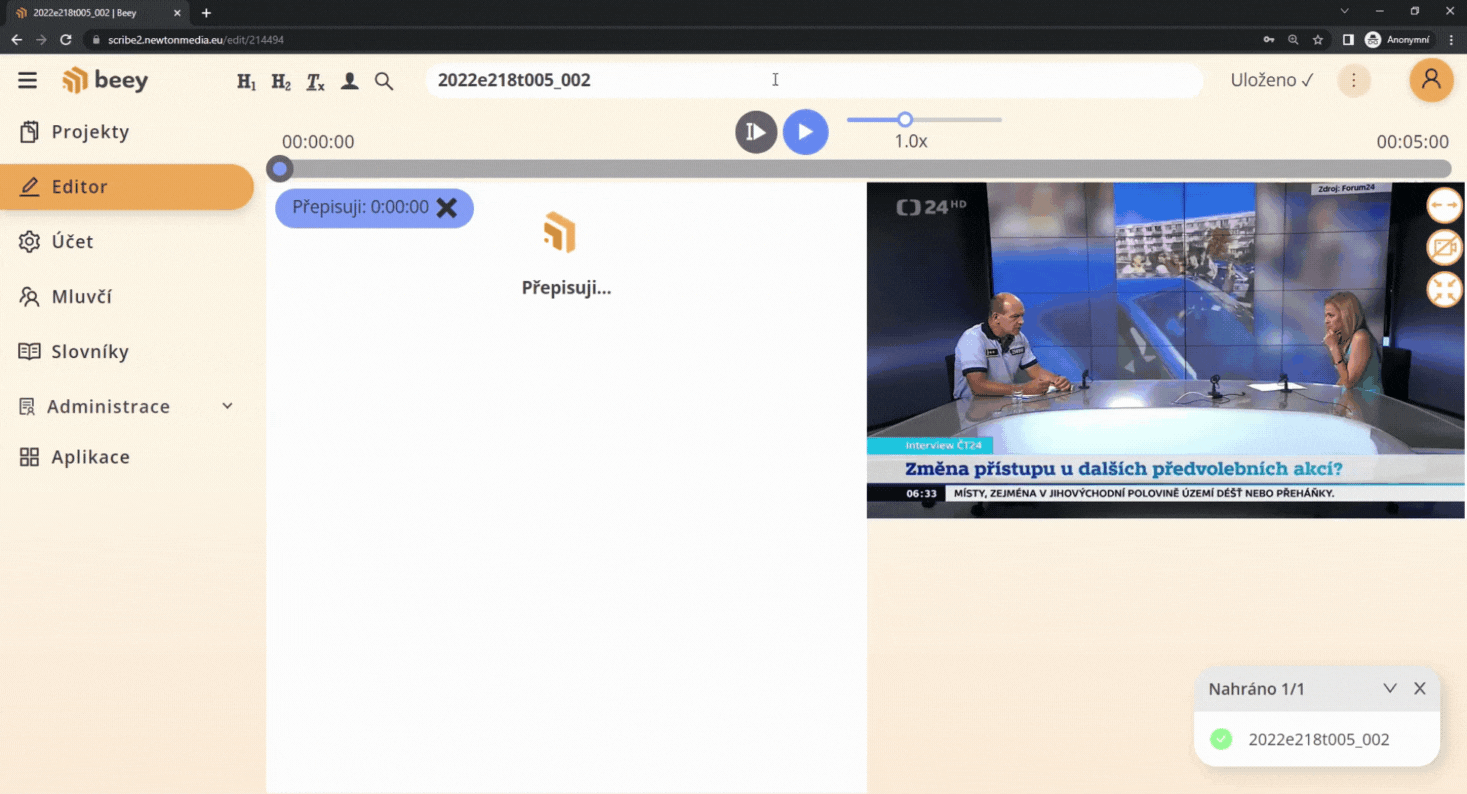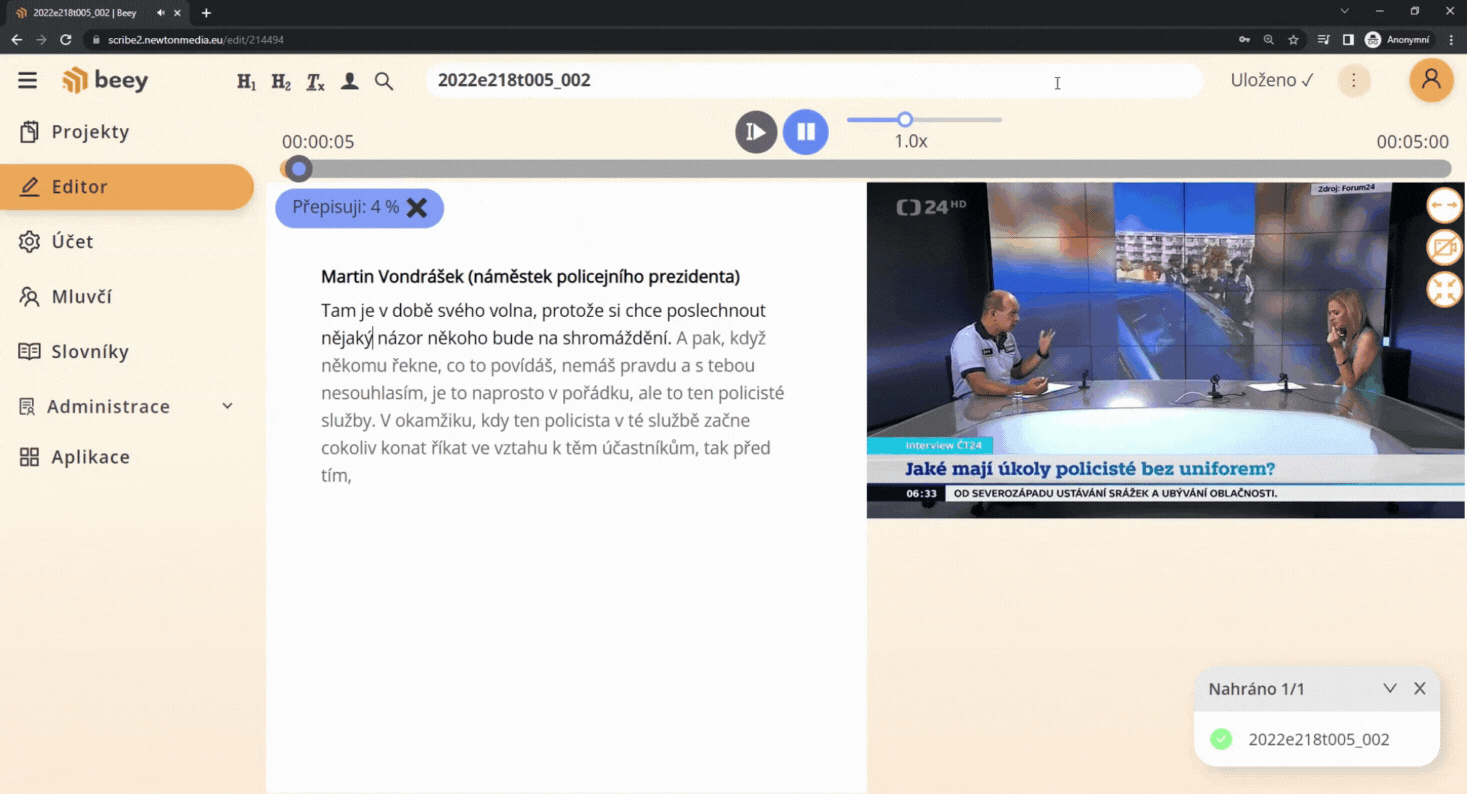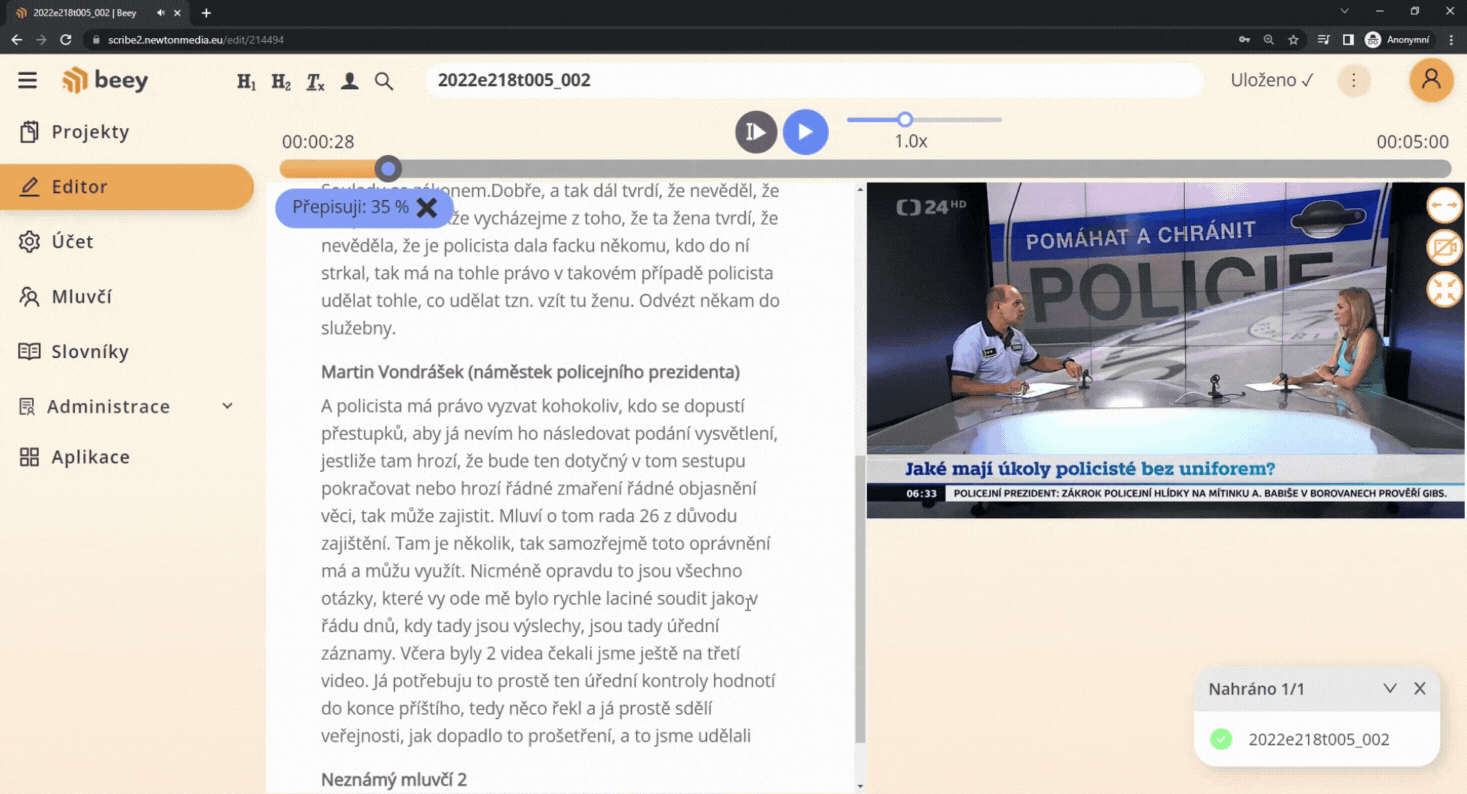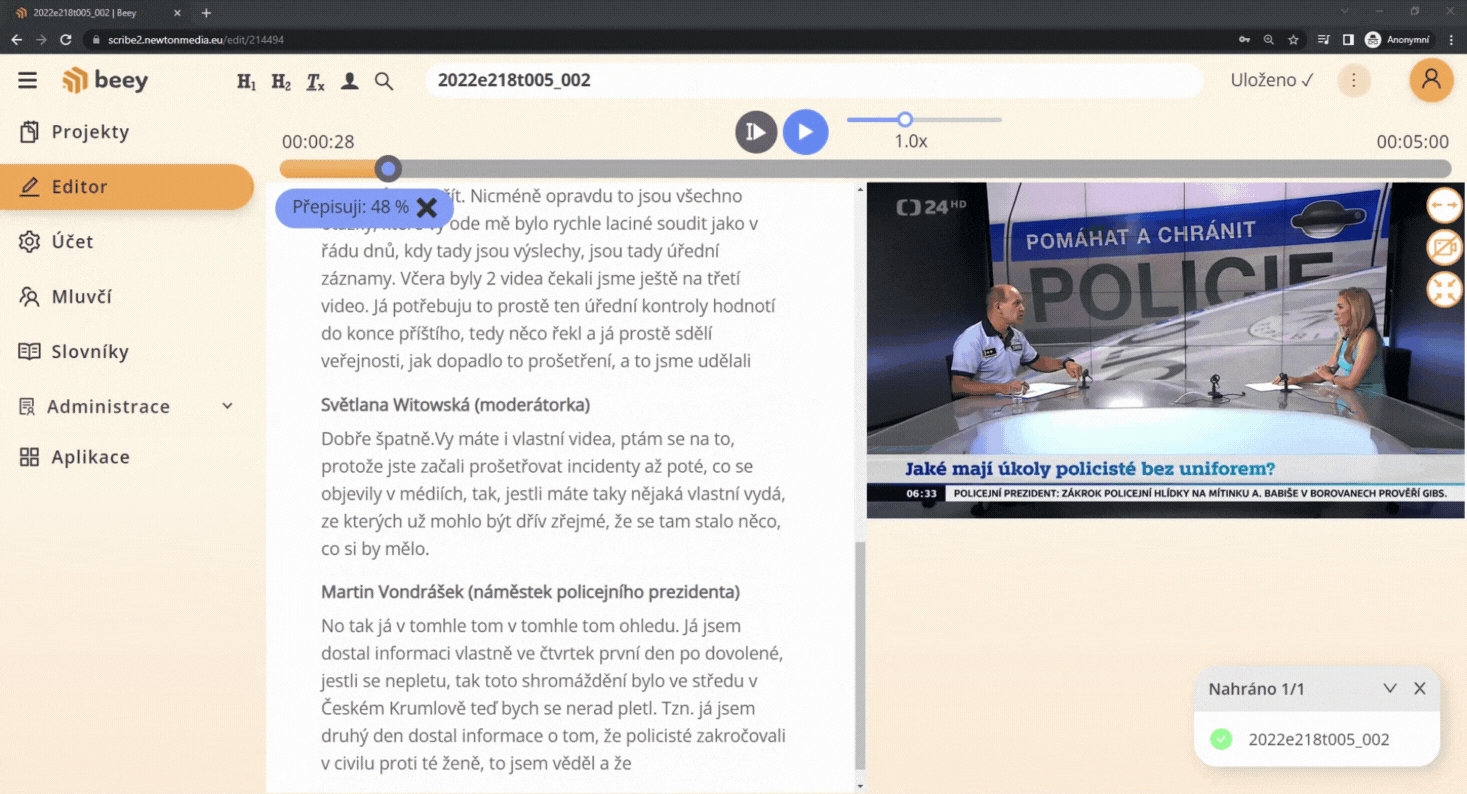
The technology is very convenient if you use plain automatic transcriptions without any manual corrections. For subsequent full-text search and keyword identification, it is desirable to have famous or frequent personalities added automatically so that you don\’t have to rely on the speaker\’s name occurring in the text, let alone being transcribed correctly.
SpeakerID technology is currently used by our sister company Newton Media. SpeakerID saves them a considerable amount of time within the daily workflow of transcription editing. In media monitoring, their editors deal mostly with a recurring group of speakers: the regular presenters, well-known personalities of the Czech political scene and show business, spokespeople and representatives of major companies. This often required a thorough research for finding out who each speaker was – but now most of these voices get automatically recognized and SpeakerID adds the person\’s name and function.
“We are very pleased with the introduction of SpeakerID. The deployment of the technology itself was quick and easy, seeing the results almost immediately. Editors were noticeably relieved, and the functionality is really precise. We have not received any complaints from users or end customers,” confirms Václav Trunec, Customer Care and Innovation Specialist for Newton Media. Based on their experience, other foreign subsidiaries and clients have become interested in our technology and we will now be able to build additional models from their data to recognize relevant people on demand.
“Due to the positive feedback and market demand, we currently want to create a database of personas from Slovenian and Austrian media. However, it is possible to create a model for any group of speakers if we are granted access to the necessary data,” informs Martin Španěl, our Research and Development Lead.
SpeakerID as such is both language- and text-independent, but – in this version – the model must be assigned to one of the supported languages in order to work in Beey. Each version of the identification software has its own private database unique to the specific client, and of course no part of the data is available to the public to ensure maximum privacy.
Have you heard of similar technology before? Would you like to learn more? Email us at [email protected]!