Stává se vám někdy, že slyšíte v rádiu nebo televizi povědomý hlas, ale nemůžete si vzpomenout, komu patří? Podobné procesy, které při vybavování takové informace probíhají ve vašem mozku, nyní umí i umělá inteligence (AI). Kombinací zpracování přirozeného jazyka (NLP) a strojového učení (ML) místo vás vyhodnotí, jestli už se systém s hlasem setkal dříve a s jakou jistotou ho dokáže přesně určit.
Rozpoznání mluvčího, jeho správné určení a ověření (speaker recognition, identification a verification) je samozřejmě již dlouho zkoumané téma. Už od devadesátých let vědci publikují studie o nových technikách, jak identifikovat konkrétní osobu jen podle hlasu, nezávisle na mluveném textu. Náš systém je založen na konvolučních neuronových sítích (CNN), které dokáží z velmi krátké nahrávky hlasu izolovat relevantní akustické údaje k vytvoření konkrétního vzorku mluvčího (voice print).
S takto vytvořenou databází — například z veřejně dostupných mediálních dat televizního a rozhlasového zpravodajství — se pak porovná nová zvuková nahrávka. Proběhne trojí kontrola podobnosti vzorků pro ujištění, že to nemůže být jiný hlas, a jméno správného mluvčího se zapíše do přepisu včetně předem uložené role (např. moderátor, ministr, reportér atd.). Pokud analyzovaný hlas není dostatečně podobný žádnému z voice printů v databázi, nebo je velmi podobný více než jednomu, systém mluvčího raději nechá nerozpoznaného, aby nedocházelo k chybné identifikaci.

Databáze voice printů se tvoří pro konkrétního zákazníka na míru, s nikým tedy nesdílíme informace o mluvčích ani nezveřejňujeme údaje o jejich hlasech. Tyto údaje však průběžně aktualizujeme, jelikož i hlas se může v průběhu života nepatrně měnit, stejně jako nahrávací technologie. Přidávání nových vzorků k již uloženým mluvčím tedy pomáhá s přesností budoucí pozitivní identifikace.
V čem všem vám může SpeakerID zjednodušit práci?
Automatické doplnění jména mluvčího v nahrávce a jeho funkce má mnoho výhod, jako například zlepšení přesnosti. V některých případech totiž ruční identifikace zahrnuje zdlouhavé vyhledávání, pokud se nejedná o výrazně specifický hlas. Často také můžou nastat komplikace v psané formě daného jména – se SpeakerID vám nehrozí překlepy nebo záměna za podobné jméno, jelikož je název vzorku mluvčího vždy kontrolován a jeho role či funkce aktualizována. Přepisujete-li tedy například rozhovor s nějakým politikem, který několikrát změnil svou pozici v rámci strany, zobrazí se vám jeho nejnovější role.
Dále vám SpeakerID pomůže, pokud přepisujete třeba pouze část pořadu či rozhovoru a nedaří se vám najít jméno moderátora či známého hosta, který se této části účastnil. Urychlí práci editora i tím, že mluvčího dosadí do všech míst, kde promlouvá – neurčí ho pouze při prvním výskytu.
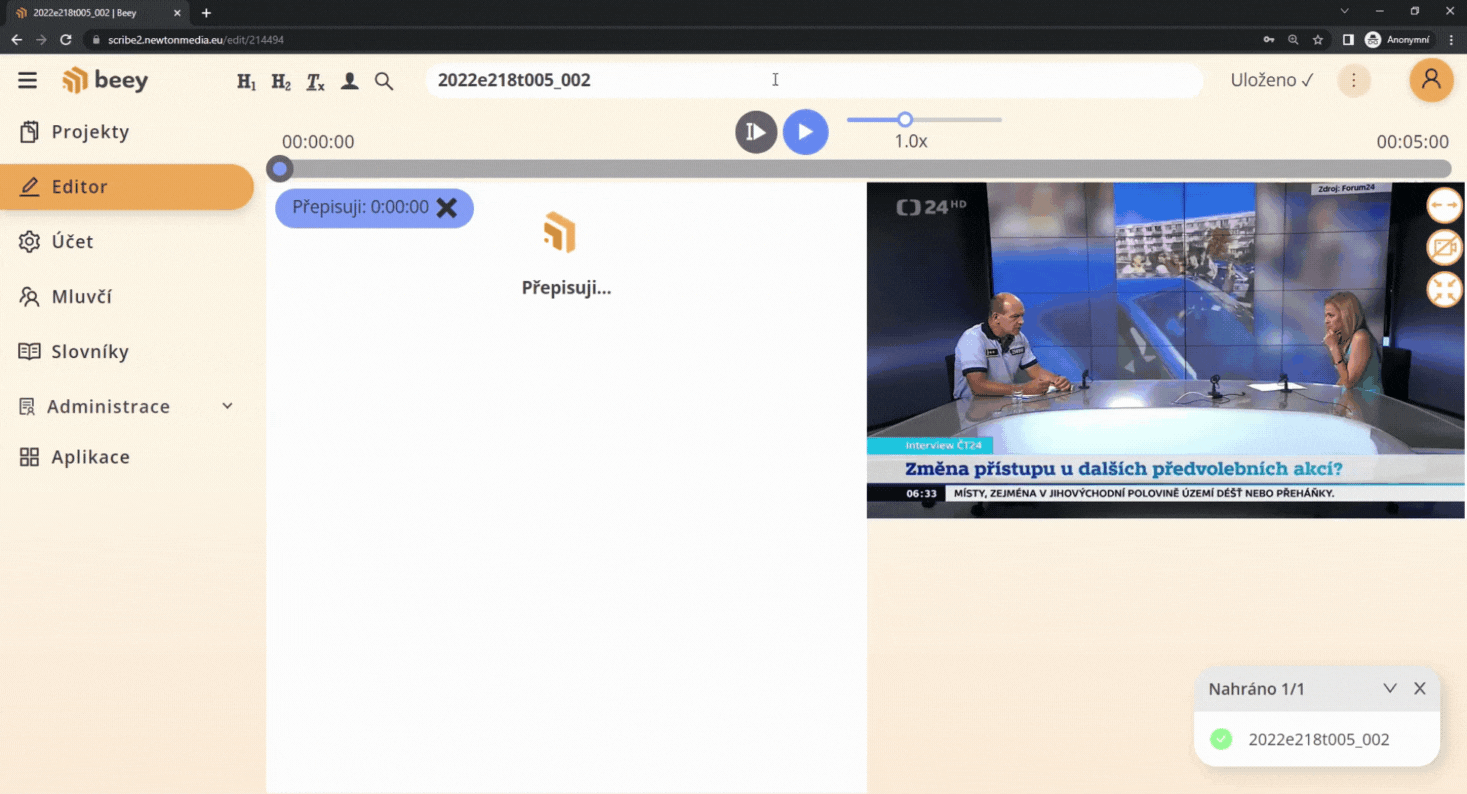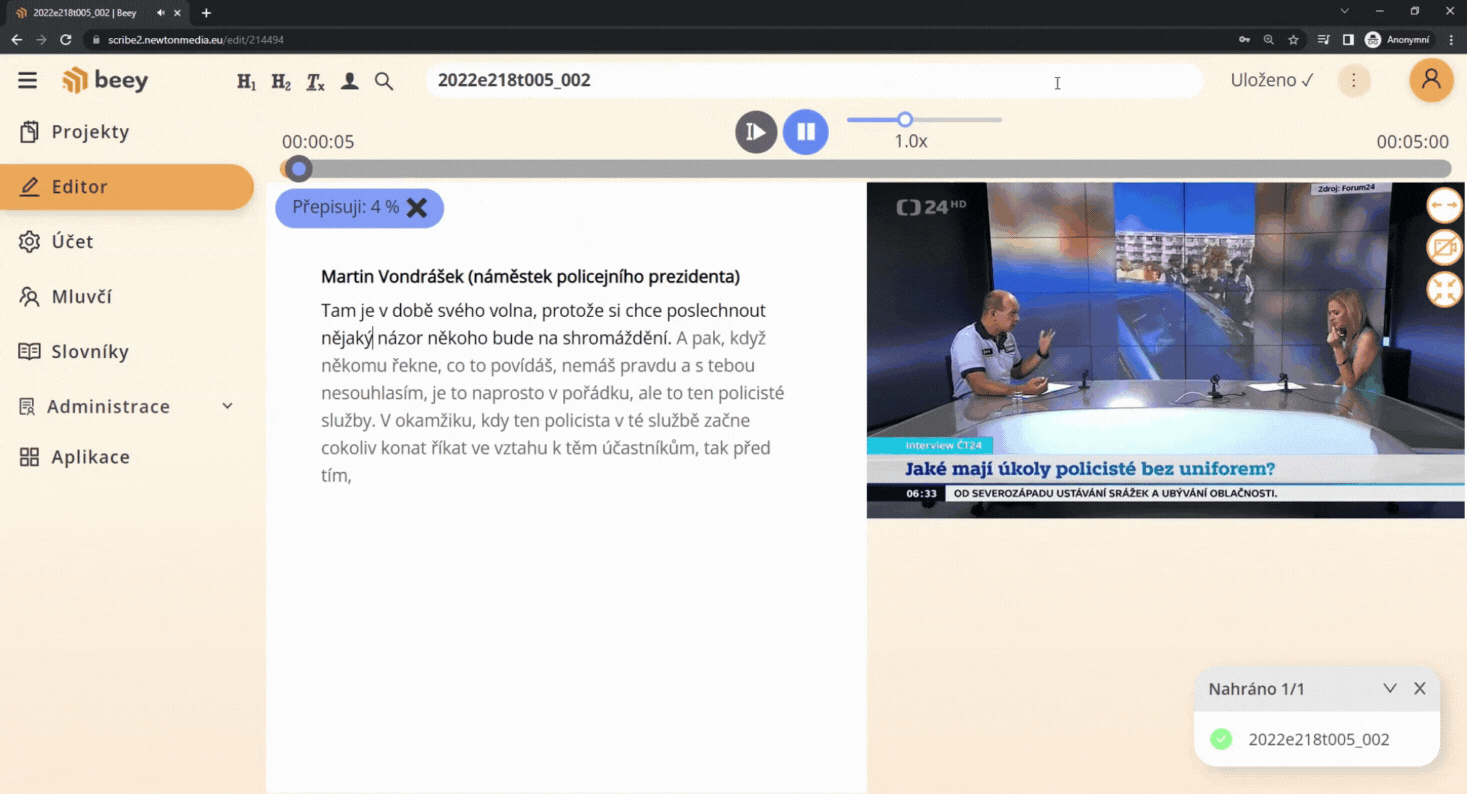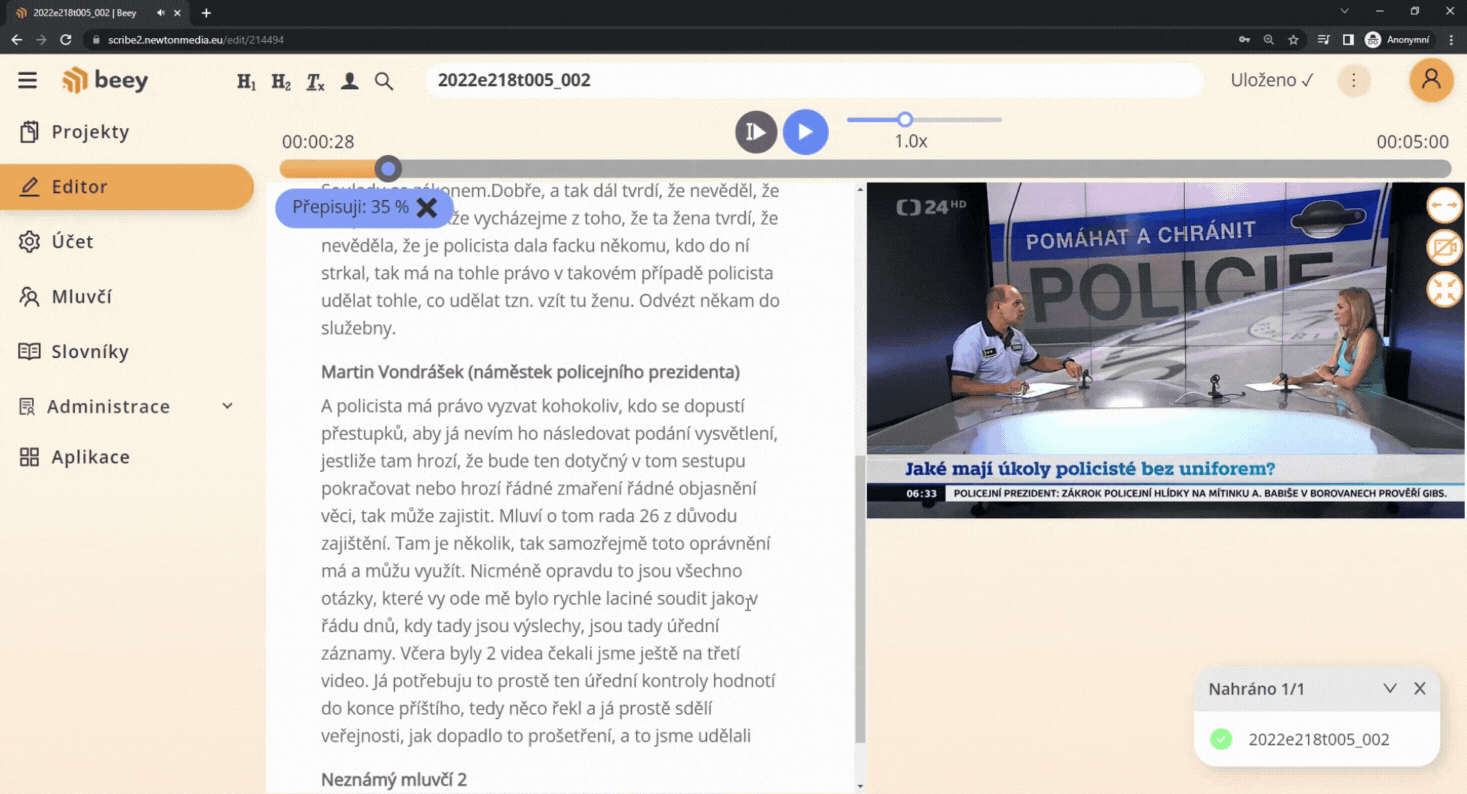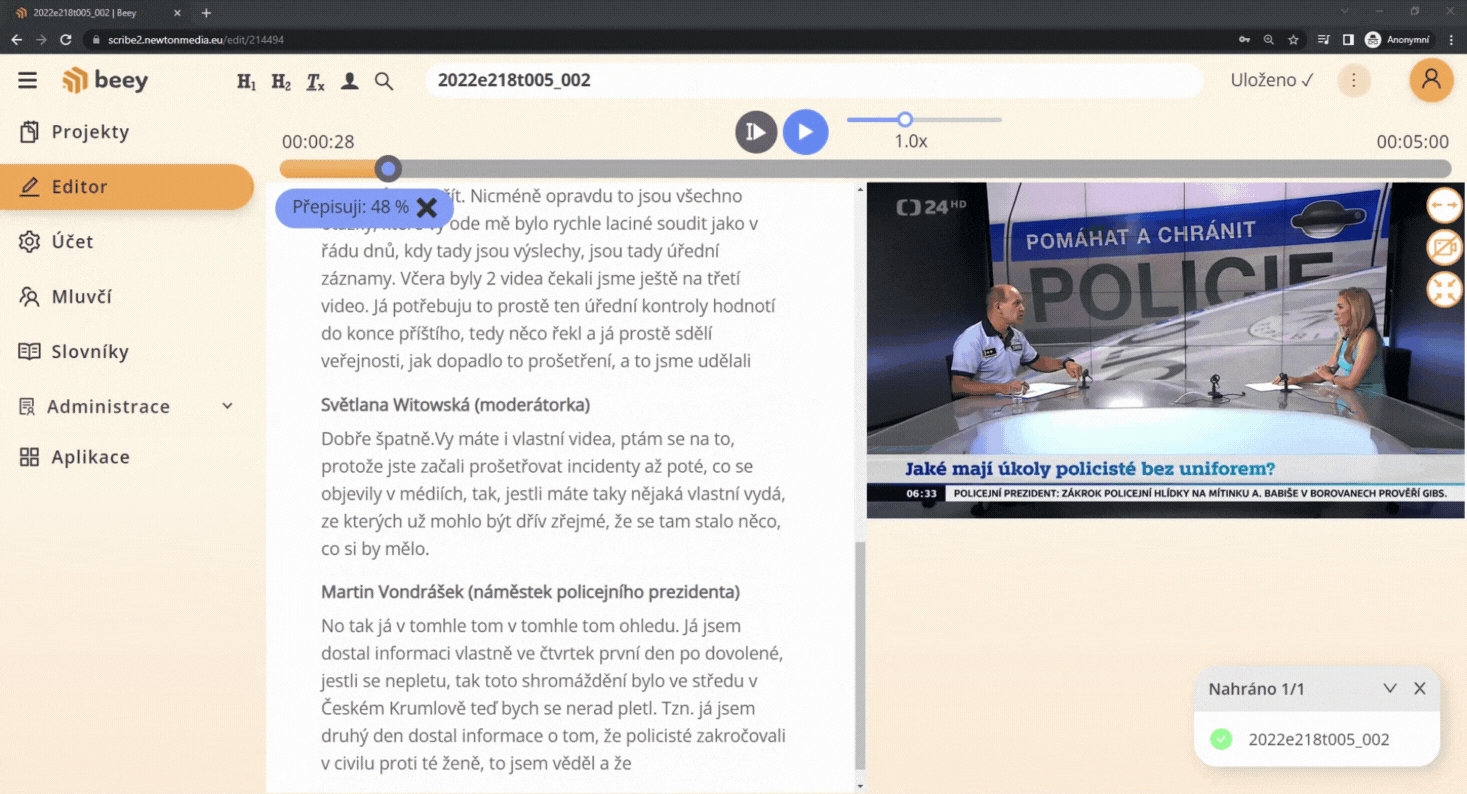
V neposlední řadě je tato technologie velmi výhodná, pokud využíváte čistě automatické přepisy bez ručních oprav editorů. Pro následné vyhledávání a určení klíčových slov je užitečné, pokud jsou známé či frekventované osobnosti automaticky doplněny a nemusíte spoléhat na to, zda se v textu jméno mluvčího vůbec objeví, natož i správně rozpozná při přepisu.
Technologii SpeakerID momentálně používají například v naší sesterské společnosti Newton Media. V pravidelných editacích přepisů, které u nich denně probíhají, jim SpeakerID šetří znatelné množství času. Při monitoringu médií se totiž setkávají s opakující se skupinou mluvčích: obvyklí moderátoři, známé osobnosti české politické scény a showbyznysu, tiskoví mluvčí a zástupci významných společností. Editoři těchto nahrávek často museli zdlouhavě vyhledávat, o koho se v daném pořadu jedná – nyní se jim však většina těchto hlasů rozpozná a SpeakerID samo doplní jméno a funkci osoby.
„Se zavedením SpeakerID jsme velmi spokojeni. Nasazení samotné technologie bylo rychlé a snadné, výsledky byly vidět prakticky okamžitě. Editorům se znatelně ulevilo a funkce je opravdu kvalitní. Nedostaly se k nám žádné stížnosti ze strany uživatelů ani koncových zákazníků,“ potvrzuje Václav Trunec, specialista na inovace a komunikaci se zákazníky pro Newton Media. Na základě jejich zkušeností se o naši technologii začaly zajímat i další zahraniční pobočky a klienti, z jejichž dat budeme nyní na vyžádání moci sestavovat nové modely k rozpoznání pro ně relevantních osob.
„Vzhledem ke kladné odezvě a současné poptávce na trhu chceme momentálně vytvořit databázi osobností ze slovinských, případně rakouských médií. Při dostatečném množství kvalitních dat však není problém vytvořit model pro jakoukoliv skupinu mluvčích,“ informuje Martin Španěl, šéf našeho vývoje a výzkumu.
SpeakerID samo o sobě není vůbec závislé na jazyce ani obsahu promluvy, pro zprovoznění v rámci Beey je však v této verzi třeba přiřadit konkrétní model k jednomu z podporovaných jazyků. Každá verze identifikátoru má svou vlastní soukromou databázi jedinečnou pro daného klienta a žádná její část ani údaje samozřejmě nejsou veřejně dostupné pro zajištění maximálního soukromí.
Už jste o podobné technologii slyšeli? Chtěli byste se dozvědět víc? Napište nám na [email protected]!