Automatický rozpoznávač řeči (ASR) je program, který pomocí algoritmů strojového učení převede zvukovou stopu do psané podoby (speech-to-text). Tu je možné následně využít pro celou řadu dalších funkcí, od editace přepsaného textu a dělení na části podle jednotlivých mluvčích, po automatickou tvorbu titulků k videím. Kvalita automatického přepisu z rozpoznávače se však může výrazně snížit v případě nekvalitní zvukové nahrávky.
Jak funguje nové rozpoznávání Beey
Původní rozpoznávače fungují na bázi slovníku. Obsahují seznam stovek tisíců slov v jejich psané podobě s odpovídající výslovností. Tuto výslovnost rozpoznávač porovná s konkrétním audiozáznamem a najde ve svém slovníku takové slovo, které svou výslovností nejlépe odpovídá. Funguje obvykle poměrně spolehlivě, má však i některé nevýhody:
- Nebere v potaz širší významový kontext slova, pouze jeho zvukovou podobu
- Nedokáže se vypořádat se slovy, které nemá v databázi – nahradí je nějakým zvukově podobným slovem
- Je třeba ho neustále spravovat a aktualizovat, aby zahrnoval i nově vznikající slova či méně častá/přejatá jména
Nový typ rozpoznávače většinu těchto problémů řešit vůbec nemusí. Přeskakuje totiž tu část databáze, která se zabývá výslovností. Je založen na principu neuronových sítí – tzv. strojové učení či umělá inteligence využívající obrovské množství dat, na kterých se algoritmy naučí rozpoznat, jaká část psaného textu odpovídá kterému zvuku. Jelikož tento rozpoznávač neobsahuje žádný fixní slovník ani konkrétní databázi pojmů, je schopný rozpoznat (nebo se k nim alespoň přiblížit) i slova, se kterými se nikdy nesetkal.
V praxi lze rozdíl mezi oběma typy rozpoznávání (kromě přesnosti) vidět na první pohled, pokud na něj aplikujete kontrolu pravopisu. Zatímco původní slovníkový model neměl prakticky žádné pravopisné chyby, jelikož používal pouze schválená slova ze slovníku, nový neuronový model může obsahovat „překlepy“ a neexistující slova, pokud narazí například na přeřeknutí mluvčích ve zvukové stopě. Může to znít jako nevýhoda, ale ve skutečnosti to spíše usnadní práci editora – problematická slova se mu hned zvýrazní. U předchozího modelu byla všechna slova sice pravopisně správně, ale mohla být špatně dosazená do kontextu, což editor pravděpodobně nezjistí bez pozorného čtení a poslechu nahrávky.
Ukázka přepisu pomocí staršího modelu rozpoznávače 
Ukázka přepisu pomocí nového modelu rozpoznávače
Zlepšení až o 10 % s novým modelem
Abychom si ověřili, že jsou výsledky přepisu s novým rozpoznávačem skutečně lepší, otestovali jsme několik náhodných zvukových souborů různého druhu: zpravodajství, záznam telefonního hovoru, video z YouTube, záznamy z jednání parlamentu a státní správy, televizní zprávy a publicistiku. Automatický přepis těchto nahrávek jsme porovnali s doslovnými, ručně připravenými přepisy. Jak se zvyšuje přesnost výsledků rozpoznání, tím je i těžší dosáhnout výraznějších změn, a tedy i malé zlepšení znamená důležitý pokrok. Neočekávali jsme příliš znatelné rozdíly, výsledky ale předčily očekávání: Průměr přesnosti přepisu starého modelu byl 83,60 %, nový model byl o více než 9 procentních bodů lepší s přesností 92,65 %. To je přibližně o 1 chybu na každých 10 slov méně!
Beey vs. Microsoft vs. Google
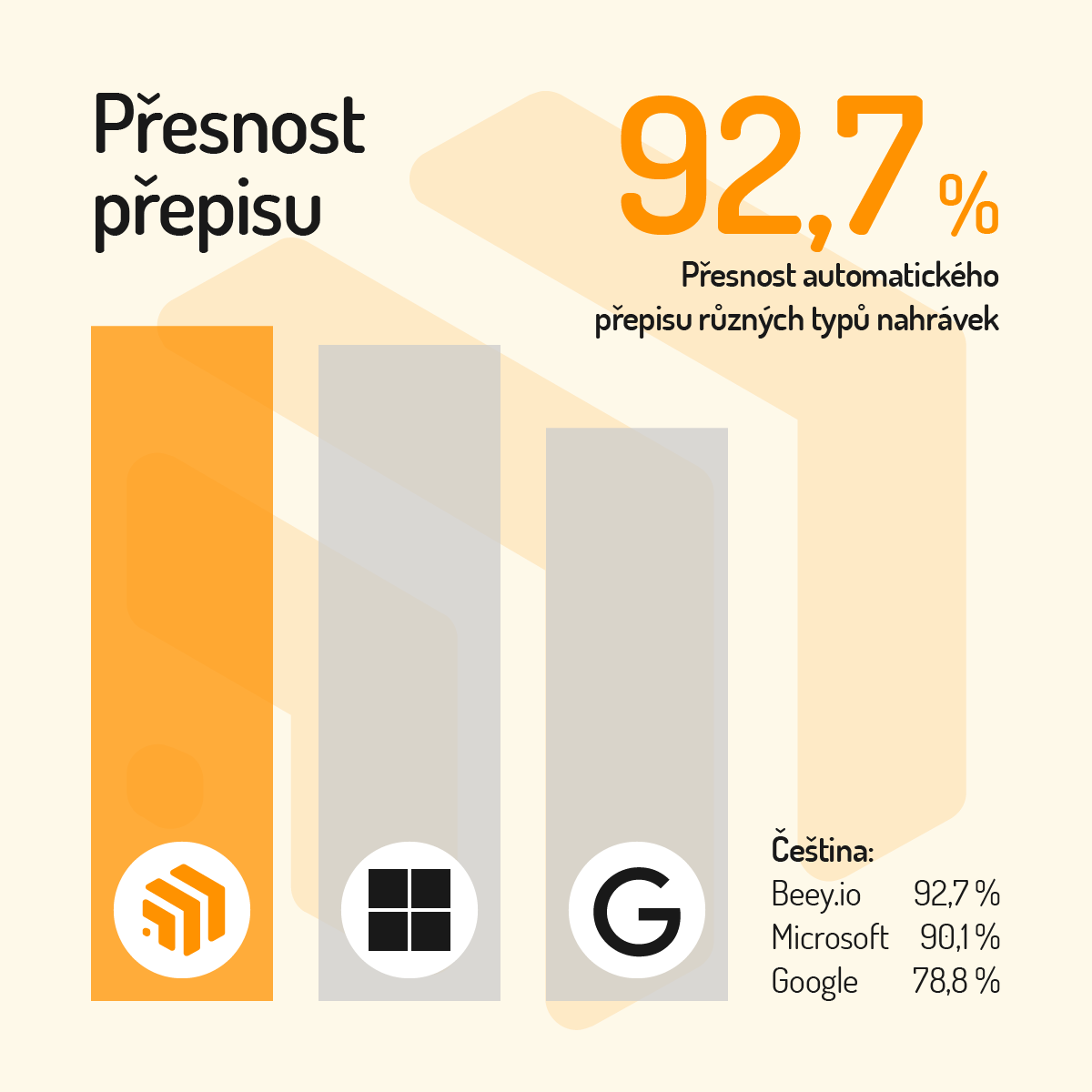
Dále nás samozřejmě zajímalo, jak si Beey vede v porovnání s konkurencí. Velká část zahraničních rozpoznávačů nepodporuje češtinu, proto jsme se soustředili na nejpoužívanější rozpoznávače firem Google a Microsoft. Zde nás čekala skvělá zpráva: Na stejných testovacích datech, kde náš rozpoznávač v Beey dosáhl přesnosti 92,65 %, měl Microsoft úspěšnost 90,07 % a Google dokonce pouze 78,74 %, tedy ještě méně než náš původní model. Navíc se nejedná o úplně ideální nahrávky ve studiové kvalitě s nulovým šumem v pozadí, ale o veřejně dostupné záznamy z českých médií. S ohledem na velikost a rozpočet na vývoj těchto nadnárodních firem lze náš výsledek pokládat za mimořádný úspěch.
Vzhledem k tomu, že Beey nepůsobí jen na českém trhu, chtěli jsme zjistit, jak obstojí i u dalších jazyků. Otestovali jsme tedy podobně různorodé ukázky nahrávek i pro angličtinu a němčinu. Zde už byly mezi výsledky menší rozdíly. Celková přesnost rozpoznávače Microsoftu byla u angličtiny lepší než přesnost našeho rozpoznávače – 92,93 % oproti 92,24 %, tedy liší se o méně než 1 %! U němčiny, kterou v poslední době intenzivně zlepšujeme, jsme naopak dopadli lépe. Beey dosáhlo 92,51 % přesnosti, kde Microsoft měl 86,88 % – rozdíl tedy více než 5 %. Služba od Googlu nadále zaostává – u němčiny s 80,18 % a u angličtiny dokonce s výsledkem pouhých 77,51 %.
Beey se rozhodně mezi světovou konkurencí neztratí! Nový model neuronového rozpoznávání ve spolupráci s libereckou SpeechLab intenzivně připravujeme i pro další jazyky: Zatím umíme norštinu, slovenštinu a ruštinu a brzy i polštinu. Ostatní jazyky jsou prozatím dostupné v původní verzi rozpoznávače, kterou ale i nadále aktualizujeme a zlepšujeme.
Nadstavbové funkce
Další výhody nad rámec samotného rozpoznávače jsou specifické funkce editoru Beey. Kromě přepisu umí i interpunkci a velká písmena, na které se při testování úspěšnosti přepisu nebere zřetel. Rozdělí text podle mluvčích, kterým lze i přiřadit roli v rámci nahrávky (např. moderátor) a uložit si je pro další použití. Umí výsledný přepis exportovat do načasovaných titulků. Umožňuje editaci souběžně s přepisem, což oceníte zejména u delších nahrávek. Synchronizace pohybu kurzoru s přehráváním audio stopy umožňuje snadno přeskočit na nejasné úseky textu a případně si zvuk zpomalit pro snazší rozklíčování.
Dále si používání Beey můžete usnadnit nadstavbovými aplikacemi Link (pro přepis souboru například z YouTube nebo Facebooku s použitím URL adresy), Stream (pro přepis živého vysílání) a Splitter (rozdělení velmi dlouhých nahrávek pro jednodušší zpracování).
Využití Beey
Aplikace Beey má už přes osm tisíc uživatelů. Oblíbili si ji novináři na přepisy rozhovorů a archivaci nahrávek; pro monitoring TV a rozhlasu ji využívá například rakouská mediální společnost APA. Beey titulkuje internetovou televizi DVTV a Televizi Seznam. Naši editoři připravují profesionální titulky i pro pořady TV NOVA a TV Prima. Mezi uživateli jsou také obce, města a státní úřady.
Chcete si sami vyzkoušet, jak Beey převádí nahrávky a porovnat výsledky s ostatními službami? Napište nám na [email protected]. Poskytneme vám přístup do naší aplikace i testovací nahrávky.